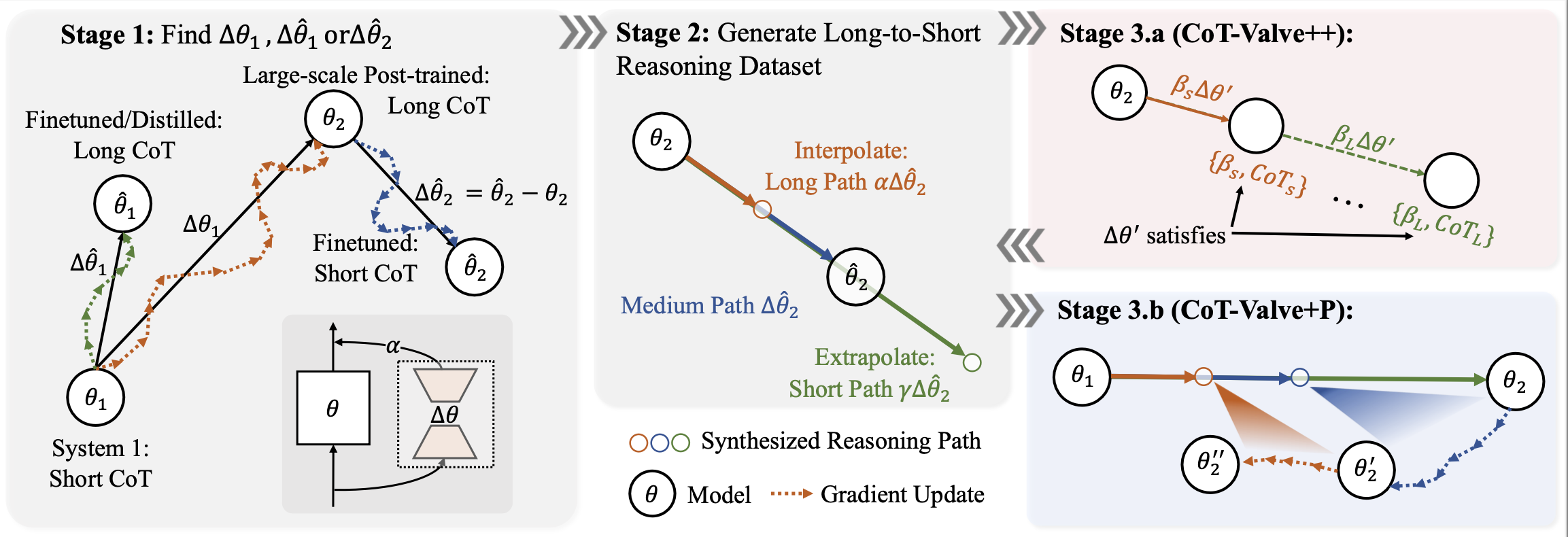
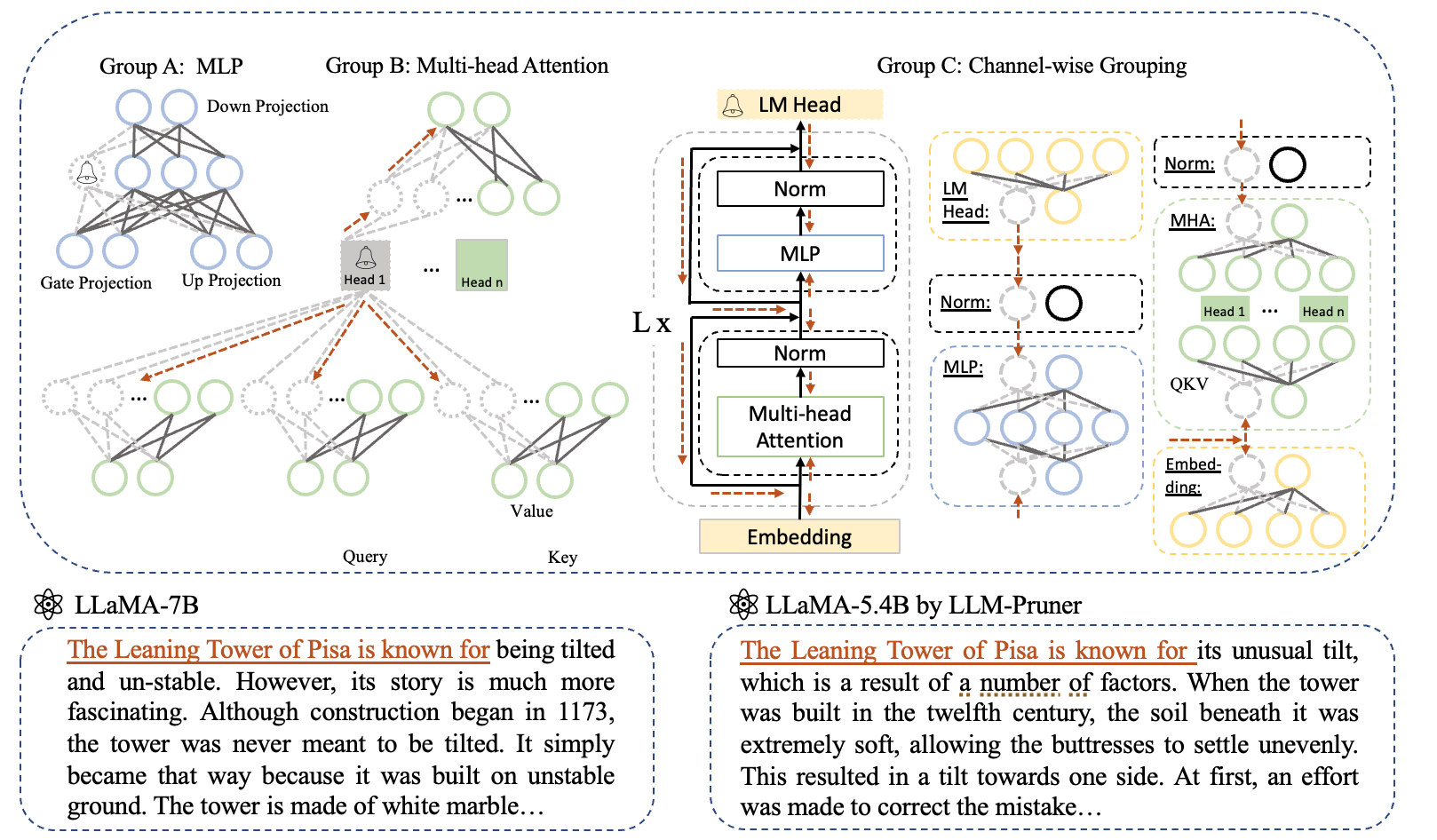
-
Diffusion Model is Effectively Its Own Teacher. CVPR 2025.
[paper]
[abstract]
In this paper, we introduce a novel self-distillation paradigm for improving the performance of diffusion models. Previous studies have shown that introducing a teacher to distill the diffusion model can enhance its sampling efficiency. We raise an intriguing question: can the diffusion model itself serve as its teacher to further improve the performance of itself? To this end, we propose a new paradigm called Self Step-Distillation (SSD). The core idea of SSD is to integrate the predictions or the intermediate activations of the diffusion model at each timestep with its preceding timestep through a fusion mechanism. We propose two forms, explicit SSD and implicit SSD (iSSD), to perform N-step to N-step distillation from the diffusion model itself to achieve improved image quality. We further elucidate the relationship between SSD and high-order solver, highlighting their underlying relationship. The effectiveness of SSD is validated through extensive experiments on diffusion transformers of various sizes and across different sampling steps. Our results show that this novel self-distillation paradigm can significantly enhance performance. Additionally, our method is compatible with the distillation method designed for few-step inference. Notably, with iSSD trained less than one epoch, we obtain a 32-step DiT-XL/2 achieving an FID of 1.99, outperforming the original 250-step DiT-XL/2 with an FID of 2.26. We further validate the effectiveness of our method on text-to-image diffusion models, such as Stable Diffusion, and also observe notable improvement in image quality.
Xinyin Ma, Runpeng Yu, Songhua Liu, Gongfan Fang, Xinchao Wang.
-
Prompting to distill: Boosting Data-Free Knowledge Distillation via Reinforced Prompt. IJCAI 2022.
[paper]
[abstract]
Data-free knowledge distillation (DFKD) conducts knowledge distillation via eliminating the dependence of original training data, and has recently achieved impressive results in accelerating pre-trained language models. At the heart of DFKD is toreconstruct a synthetic dataset by invertingthe parameters of the uncompressed model. Prior DFKD approaches, however, havelargely relied on hand-crafted priors of the target data distribution for the reconstruction, which can be inevitably biased and often incompetent to capture the intrinsic distributions. To address this problem, we propose a prompt-based method, termed as PromptDFD, that allows us to take advantage of learned language priors, which effectively harmonizes the synthetic sentences to be semantically and grammatically correct. Specifically, PromptDFD leverages a pre-trained generative model to provide language priors and introduces a reinforced topic prompter to control data synthesis, making the generated samples thematically relevant and semantically plausible, and thus friendly to downstream tasks. As shown in our experiments, the proposed method substantially improves the synthesis quality and achieves considerable improvements on distillation performance. In some cases, PromptDFD even gives rise to results on par with those from the data-driven knowledge distillation with access to the original training data.
Xinyin Ma, Xinchao Wang, Gongfan Fang, Yongliang Shen, Weiming Lu.
-
MuVER: Improving First-Stage Entity Retrieval with Multi-View Entity Representations. EMNLP 2021 Short.
[paper]
[code]
[abstract]
Entity retrieval, which aims at disambiguating mentions to canonical entities from massive KBs, is essential for many tasks in natural language processing. Recent progress in entity retrieval shows that the dual-encoder structure is a powerful and efficient framework to nominate candidates if entities are only identified by descriptions. However, they ignore the property that meanings of entity mentions diverge in different contexts and are related to various portions of descriptions, which are treated equally in previous works. In this work, we propose Multi-View Entity Representations (MuVER), a novel approach for entity retrieval that constructs multi-view representations for entity descriptions and approximates the optimal view for mentions via a heuristic searching method. Our method achieves the state-of-the-art performance on ZESHEL and improves the quality of candidates on three standard Entity Linking datasets.
Xinyin Ma, Yong Jiang, Nguyen Bach, Tao Wang, Zhongqiang Huang, Fei Huang, Weiming Lu.
-
Adversarial Self-Supervised Data-Free Distillation for Text Classification. EMNLP 2020.
[paper]
[video]
[abstract]
Large pre-trained transformer-based language models have achieved impressive results on a wide range of NLP tasks. In the past few years, Knowledge Distillation(KD) has become a popular paradigm to compress a computationally expensive model to a resource-efficient lightweight model. However, most KD algorithms, especially in NLP, rely on the accessibility of the original training dataset, which may be unavailable due to privacy issues. To tackle this problem, we propose a novel two-stage data-free distillation method, named Adversarial self-Supervised Data-Free Distillation (AS-DFD), which is designed for compressing large-scale transformer-based models (e.g., BERT). To avoid text generation in discrete space, we introduce a Plug & Play Embedding Guessing method to craft pseudo embeddings from the teacher’s hidden knowledge. Meanwhile, with a self-supervised module to quantify the student’s ability, we adapt the difficulty of pseudo embeddings in an adversarial training manner. To the best of our knowledge, our framework is the first data-free distillation framework designed for NLP tasks. We verify the effectiveness of our method on several text classification datasets.
Xinyin Ma, Yongliang Shen, Gongfan Fang, Chen Chen, Chenghao Jia, Weiming Lu.
-
Introducing Visual Perception Token into Multimodal Large Language Model. ICCV 2025.
[paper]
[code]
[abstract]
To utilize visual information, Multimodal Large Language Model (MLLM) relies on the perception process of its vision encoder. The completeness and accuracy of visual perception significantly influence the precision of spatial reasoning, fine-grained understanding, and other tasks. However, MLLM still lacks the autonomous capability to control its own visual perception processes, for example, selectively reviewing specific regions of an image or focusing on information related to specific object categories. In this work, we propose the concept of Visual Perception Token, aiming to empower MLLM with a mechanism to control its visual perception processes. We design two types of Visual Perception Tokens, termed the Region Selection Token and the Vision Re-Encoding Token. MLLMs autonomously generate these tokens, just as they generate text, and use them to trigger additional visual perception actions. The Region Selection Token explicitly identifies specific regions in an image that require further perception, while the Vision Re-Encoding Token uses its hidden states as control signals to guide additional visual perception processes. Extensive experiments demonstrate the advantages of these tokens in handling spatial reasoning, improving fine-grained understanding, and other tasks. On average, the introduction of Visual Perception Tokens improves the performance of a 2B model by 23.6%, increasing its score from 0.572 to 0.708, and even outperforms a 7B parameter model by 13.4% (from 0.624).
Runpeng Yu*, Xinyin Ma*, Xinchao Wang (*Equal Contribution)
-
Thinkless: LLM Learns When to Think. NeurIPS 2025.
[paper]
[code]
[abstract]
Reasoning Language Models, capable of extended chain-of-thought reasoning, have demonstrated remarkable performance on tasks requiring complex logical inference. However, applying elaborate reasoning for all queries often results in substantial computational inefficiencies, particularly when many problems admit straightforward solutions. This motivates an open question: Can LLMs learn when to think? To answer this, we propose Thinkless, a learnable framework that empowers an LLM to adaptively select between short-form and long-form reasoning, based on both task complexity and the model's ability. Thinkless is trained under a reinforcement learning paradigm and employs two control tokens, short for concise responses and think for detailed reasoning. At the core of our method is a Decoupled Group Relative Policy Optimization (DeGRPO) algorithm, which decomposes the learning objective of hybrid reasoning into two components: (1) a control token loss that governs the selection of the reasoning mode, and (2) a response loss that improves the accuracy of the generated answers. This decoupled formulation enables fine-grained control over the contributions of each objective, stabilizing training and effectively preventing collapse observed in vanilla GRPO. Empirically, on several benchmarks such as Minerva Algebra, MATH-500, and GSM8K, Thinkless is able to reduce the usage of long-chain thinking by 50% - 90%, significantly improving the efficiency of Reasoning Language Models.
Gongfan Fang, Xinyin Ma, Xinchao Wang.
-
VeriThinker: Learning to Verify Makes Reasoning Model Efficient. NeurIPS 2025
[paper]
[code]
[abstract]
Large Reasoning Models (LRMs) excel at complex tasks using Chain-of-Thought (CoT) reasoning. However, their tendency to overthinking leads to unnecessarily lengthy reasoning chains, dramatically increasing inference costs. To mitigate this issue, we introduce VeriThinker, a novel approach for CoT compression. Unlike conventional methods that fine-tune LRMs directly on the original reasoning task using synthetic concise CoT data, we innovatively fine-tune the model solely through an auxiliary verification task. By training LRMs to accurately verify the correctness of CoT solutions, the LRMs inherently become more discerning about the necessity of subsequent self-reflection steps, thereby effectively suppressing overthinking. Extensive experiments validate that VeriThinker substantially reduces reasoning chain lengths while maintaining or even slightly improving accuracy. When applied to DeepSeek-R1-Distill-Qwen-7B, our approach reduces reasoning tokens on MATH500 from 3790 to 2125 while improving accuracy by 0.8% (94.0% to 94.8%), and on AIME25, tokens decrease from 14321 to 10287 with a 2.1% accuracy gain (38.7% to 40.8%). Additionally, our experiments demonstrate that VeriThinker can also be zero-shot generalized to speculative reasoning.
Zigeng Chen, Xinyin Ma, Gongfan Fang, Xinchao Wang.
-
Collaborative Decoding Makes Visual Auto-Regressive Modeling Efficient. CVPR 2025
[paper]
[code]
[abstract]
In the rapidly advancing field of image generation, Visual Auto-Regressive (VAR) modeling has garnered considerable attention for its innovative next-scale prediction approach. This paradigm offers substantial improvements in efficiency, scalability, and zero-shot generalization. Yet, the inherently coarse-to-fine nature of VAR introduces a prolonged token sequence, leading to prohibitive memory consumption and computational redundancies. To address these bottlenecks, we propose Collaborative Decoding (CoDe), a novel efficient decoding strategy tailored for the VAR framework. CoDe capitalizes on two critical observations: the substantially reduced parameter demands at larger scales and the exclusive generation patterns across different scales. Based on these insights, we partition the multi-scale inference process into a seamless collaboration between a large model and a small model. The large model serves as the 'drafter', specializing in generating low-frequency content at smaller scales, while the smaller model serves as the 'refiner', solely focusing on predicting high-frequency details at larger scales. This collaboration yields remarkable efficiency with minimal impact on quality: CoDe achieves a 1.7x speedup, slashes memory usage by around 50%, and preserves image quality with only a negligible FID increase from 1.95 to 1.98. When drafting steps are further decreased, CoDe can achieve an impressive 2.9x acceleration ratio, reaching 41 images/s at 256x256 resolution on a single NVIDIA 4090 GPU, while preserving a commendable FID of 2.27
Zigeng Chen, Xinyin Ma, Gongfan Fang, Xinchao Wang.
-
TinyFusion: Diffusion Transformers Learned Shallow. CVPR 2025.
[paper]
[code]
[abstract]
Diffusion Transformers have demonstrated remarkable capabilities in image generation but often come with excessive parameterization, resulting in considerable inference overhead in real-world applications. In this work, we present TinyFusion, a depth pruning method designed to remove redundant layers from diffusion transformers via end-to-end learning. The core principle of our approach is to create a pruned model with high recoverability, allowing it to regain strong performance after fine-tuning. To accomplish this, we introduce a differentiable sampling technique to make pruning learnable, paired with a co-optimized parameter to simulate future fine-tuning. While prior works focus on minimizing loss or error after pruning, our method explicitly models and optimizes the post-fine-tuning performance of pruned models. Experimental results indicate that this learnable paradigm offers substantial benefits for layer pruning of diffusion transformers, surpassing existing importance-based and error-based methods. Additionally, TinyFusion exhibits strong generalization across diverse architectures, such as DiTs, MARs, and SiTs. Experiments with DiT-XL show that TinyFusion can craft a shallow diffusion transformer at less than 7% of the pre-training cost, achieving a 2× speedup with an FID score of 2.86, outperforming competitors with comparable efficiency
Gongfan Fang, Kunjun Li, Xinyin Ma, Xinchao Wang.
-
AsyncDiff: Parallelizing Diffusion Models by Asynchronous Denoising. NeurIPS 2024.
[paper]
[code]
[abstract]
Diffusion models have garnered significant interest from the community for their great generative ability across various applications. However, their typical multi-step sequential-denoising nature gives rise to high cumulative latency, thereby precluding the possibilities of parallel computation. To address this, we introduce AsyncDiff, a universal and plug-and-play acceleration scheme that enables model parallelism across multiple devices. Our approach divides the cumbersome noise prediction model into multiple components, assigning each to a different device. To break the dependency chain between these components, it transforms the conventional sequential denoising into an asynchronous process by exploiting the high similarity between hidden states in consecutive diffusion steps. Consequently, each component is facilitated to compute in parallel on separate devices. The proposed strategy significantly reduces inference latency while minimally impacting the generative quality. Specifically, for the Stable Diffusion v2.1, AsyncDiff achieves a 2.7x speedup with negligible degradation and a 4.0x speedup with only a slight reduction of 0.38 in CLIP Score, on four NVIDIA A5000 GPUs. Our experiments also demonstrate that AsyncDiff can be readily applied to video diffusion models with encouraging performances.
Zigeng Chen, Xinyin Ma, Gongfan Fang, Zhenxiong Tan, Xinchao Wang.
-
SlimSAM: 0.1% Data Makes Segment Anything Slim. NeurIPS 2024.
[paper]
[code]
[abstract]
Current approaches for compressing the Segment Anything Model (SAM) yield commendable results, yet necessitate extensive data to train a new network from scratch. Employing conventional pruning techniques can remarkably reduce data requirements but would suffer from a degradation in performance. To address this challenging trade-off, we introduce SlimSAM, a novel data-efficient SAM compression method that achieves superior performance with extremely less training data. The essence of SlimSAM is encapsulated in the alternate slimming framework which effectively enhances knowledge inheritance under severely limited training data availability and exceptional pruning ratio. Diverging from prior techniques, our framework progressively compresses the model by alternately pruning and distilling distinct, decoupled sub-structures. Disturbed Taylor pruning is also proposed to address the misalignment between the pruning objective and training target, thereby boosting the post-distillation after pruning. SlimSAM yields significant performance improvements while demanding over 10 times less training data than any other existing compression methods. Even when compared to the original SAM, SlimSAM achieves approaching performance while reducing parameter counts to merely 1.4% (9.1M), MACs to 0.8% (23G), and requiring only 0.1% (10k) of the SAM training data.
Zigeng Chen, Gongfan Fang, Xinyin Ma, Xinchao Wang.
-
Remix-DiT: Mixing Diffusion Transformers for Multi-Expert Denoising. NeurIPS 2024.
[paper]
[code]
[abstract]
Transformer-based diffusion models have achieved significant advancements across a variety of generative tasks. However, producing high-quality outputs typically necessitates large transformer models, which result in substantial training and inference overhead. In this work, we investigate an alternative approach involving multiple experts for denoising, and introduce RemixDiT, a novel method designed to enhance output quality at a low cost. The goal of RemixDiT is to craft N diffusion experts for different denoising timesteps, yet without the need for expensive training of N independent models. To achieve this, RemixDiT employs K basis models (where K < N) and utilizes learnable mixing coefficients to adaptively craft expert models. This design offers two significant advantages: first, although the total model size is increased, the model produced by the mixing operation shares the same architecture as a plain model, making the overall model as efficient as a standard diffusion transformer. Second, the learnable mixing adaptively allocates model capacity across timesteps, thereby effectively improving generation quality. Experiments conducted on the ImageNet dataset demonstrate that RemixDiT achieves promising results compared to standard diffusion transformers and other multiple-expert methods.
Gongfan Fang, Xinyin Ma, Xinchao Wang.
-
Isomorphic Pruning for Vision Models. ECCV 2024.
[paper]
[code]
[abstract]
Structured pruning reduces the computational overhead of deep neural networks by removing redundant sub-structures. However, assessing the relative importance of different sub-structures remains a significant challenge, particularly in advanced vision models featuring novel mechanisms and architectures like self-attention, depth-wise convolutions, or residual connections. These heterogeneous substructures usually exhibit diverged parameter scales, weight distributions, and computational topology, introducing considerable difficulty to importance comparison. To overcome this, we present Isomorphic Pruning, a simple approach that demonstrates effectiveness across a range of network architectures such as Vision Transformers and CNNs, and delivers competitive performance across different model sizes. Isomorphic Pruning originates from an observation that, when evaluated under a pre-defined importance criterion, heterogeneous sub-structures demonstrate significant divergence in their importance distribution, as opposed to isomorphic structures that present similar importance patterns. This inspires us to perform isolated ranking and comparison on different types of sub-structures for more reliable pruning. Our empirical results on ImageNet-1K demonstrate that Isomorphic Pruning surpasses several pruning baselines dedicatedly designed for Transformers or CNNs. For instance, we improve the accuracy of DeiT-Tiny from 74.52% to 77.50% by pruning an off-the-shelf DeiT-Base model. And for ConvNext-Tiny, we enhanced performance from 82.06% to 82.18%, while reducing the number of parameters and memory usage.
Gongfan Fang, Xinyin Ma, Michael Bi Mi, Xinchao Wang.
-
LiteFocus: Accelerated Diffusion Inference for Long Audio Synthesis. Interspeech 2024.
[paper]
[code]
[abstract]
Latent diffusion models have shown promising results in audio generation, making notable advancements over traditional methods. However, their performance, while impressive with short audio clips, faces challenges when extended to longer audio sequences. These challenges are due to model's self-attention mechanism and training predominantly on 10-second clips, which complicates the extension to longer audio without adaptation. In response to these issues, we introduce a novel approach, LiteFocus that enhances the inference of existing audio latent diffusion models in long audio synthesis. Observed the attention pattern in self-attention, we employ a dual sparse form for attention calculation, designated as same-frequency focus and cross-frequency compensation, which curtails the attention computation under same-frequency constraints, while enhancing audio quality through cross-frequency refillment. LiteFocus demonstrates substantial reduction on inference time with diffusion-based TTA model by 1.99x in synthesizing 80-second audio clips while also obtaining improved audio quality.
Zhenxiong Tan, Xinyin Ma, Gongfan Fang, Xinchao Wang.
-
DepGraph: Towards Any Structural Pruning. CVPR 2023.
[paper]
[code]
[abstract]
Structural pruning enables model acceleration by removing structurally-grouped parameters from neural networks. However, the parameter-grouping patterns vary widely across different models, making architecture-specific pruners, which rely on manually-designed grouping schemes, non-generalizable to new architectures. In this work, we study a highly-challenging yet barely-explored task, any structural pruning, to tackle general structural pruning of arbitrary architecture like CNNs, RNNs, GNNs and Transformers. The most prominent obstacle towards this goal lies in the structural coupling, which not only forces different layers to be pruned simultaneously, but also expects all removed parameters to be consistently unimportant, thereby avoiding structural issues and significant performance degradation after pruning. To address this problem, we propose a general and fully automatic method, Dependency Graph(DepGraph), to explicitly model the dependency between layers and comprehensively group coupled parameters for pruning. In this work, we extensively evaluate our method on several architectures and tasks, including ResNe(X)t, DenseNet, MobileNet and Vision transformer for images, GAT for graph, DGCNN for 3D point cloud, alongside LSTM for language, and demonstrate that, even with a simple norm-based criterion, the proposed method consistently yields gratifying performances.

Gongfan Fang, Xinyin Ma, Mingli Song, Michael Bi Mi, Xinchao Wang.
-
Structural Pruning for Diffusion Models. NeurIPS 2023.
[paper]
[code]
[abstract]
Generative modeling has recently undergone remarkable advancements, primarily propelled by the transformative implications of Diffusion Probabilistic Models (DPMs). The impressive capability of these models, however, often entails significant computational overhead during both training and inference. To tackle this challenge, we present Diff-Pruning, an efficient compression method tailored for learning lightweight diffusion models from pre-existing ones, without the need for extensive re-training. The essence of Diff-Pruning is encapsulated in a Taylor expansion over pruned timesteps, a process that disregards non-contributory diffusion steps and ensembles informative gradients to identify important weights. Our empirical assessment, undertaken across four diverse datasets highlights two primary benefits of our proposed method: 1) Efficiency: it enables approximately a 50% reduction in FLOPs at a mere 10% to 20% of the original training expenditure; 2) Consistency: the pruned diffusion models inherently preserve generative behavior congruent with their pre-trained progenitors.
Gongfan Fang, Xinyin Ma, Xinchao Wang.
-
A Locate and Label: A Two-stage Identifier for Nested Named Entity Recognition. ACL2021.
[paper]
[code]
[abstract]
Named entity recognition (NER) is a well-studied task in natural language processing. Traditional NER research only deals with flat entities and ignores nested entities. The span-based methods treat entity recognition as a span classification task. Although these methods have the innate ability to handle nested NER, they suffer from high computational cost, ignorance of boundary information, under-utilization of the spans that partially match with entities, and difficulties in long entity recognition. To tackle these issues, we propose a two-stage entity identifier. First we generate span proposals by filtering and boundary regression on the seed spans to locate the entities, and then label the boundary-adjusted span proposals with the corresponding categories. Our method effectively utilizes the boundary information of entities and partially matched spans during training. Through boundary regression, entities of any length can be covered theoretically, which improves the ability to recognize long entities. In addition, many low-quality seed spans are filtered out in the first stage, which reduces the time complexity of inference. Experiments on nested NER datasets demonstrate that our proposed method outperforms previous state-of-the-art models.
Yongliang Shen, Xinyin Ma, Zeqi Tan, Shuai Zhang, Wen Wang, Weiming Lu.
-
A Trigger-Sense Memory Flow Framework for Joint Entity and Relation Extraction. WWW 2021.
[paper]
[code]
[abstract]
Joint entity and relation extraction framework constructs a unified model to perform entity recognition and relation extraction simultaneously, which can exploit the dependency between the two tasks to mitigate the error propagation problem suffered by the pipeline model. Current efforts on joint entity and relation extraction focus on enhancing the interaction between entity recognition and relation extraction through parameter sharing, joint decoding, or other ad-hoc tricks (e.g., modeled as a semi-Markov decision process, cast as a multi-round reading comprehension task). However, there are still two issues on the table. First, the interaction utilized by most methods is still weak and uni-directional, which is unable to model the mutual dependency between the two tasks. Second, relation triggers are ignored by most methods, which can help explain why humans would extract a relation in the sentence. They’re essential for relation extraction but overlooked. To this end, we present a Trigger-Sense Memory Flow Framework (TriMF) for joint entity and relation extraction. We build a memory module to remember category representations learned in entity recognition and relation extraction tasks. And based on it, we design a multi-level memory flow attention mechanism to enhance the bi-directional interaction between entity recognition and relation extraction. Moreover, without any human annotations, our model can enhance relation trigger information in a sentence through a trigger sensor module, which improves the model performance and makes model predictions with better interpretation. Experiment results show that our proposed framework achieves state-of-the-art results by improves the relation F1 to 52.44% (+3.2%) on SciERC, 66.49% (+4.9%) on ACE05, 72.35% (+0.6%) on CoNLL04 and 80.66% (+2.3%) on ADE.
Yongliang Shen, Xinyin Ma, Yechun Tang, Weiming Lu.